Python 배열(list)을 다룰 때 유용한 함수
Python에서 list는 가장 많이 사용되는 자료형 중 하나로, 다양한 내장 함수들을 제공합니다. 이 글에서는 Python의 list 자료형을 다룰 때 유용한 함수에 대해 설명합니다.

1. 리스트 생성 및 기본 연산
1.1. 리스트 생성
리스트는 대괄호 []를 사용하여 생성할 수 있습니다.
1
2
3
4
5
# 빈 리스트 생성
empty_list = []
# 요소가 있는 리스트 생성
fruits = ['apple', 'banana', 'cherry']
1.2. 리스트 길이 (len)
리스트의 길이는 len() 함수를 사용하여 확인할 수 있습니다.
1
2
fruits = ['apple', 'banana', 'cherry']
print(len(fruits)) # 출력: 3
1.3. 리스트 요소 접근
index를 사용하여 리스트의 요소에 접근할 수 있습니다.
1
2
3
print(fruits[0]) # 출력: apple
print(fruits[1]) # 출력: banana
print(fruits[2]) # 출력: cherry
2. 요소 삽입/수정/삭제 메서드
2.1. append()
append() 메서드는 리스트의 끝에 요소를 추가합니다.
1
2
3
4
fruits = ['apple', 'banana', 'cherry']
fruits.append('elderberry')
print(fruits) # 출력: ['apple', 'banana', 'cherry', 'elderberry']
2.2. extend()
extend() 메서드는 다른 리스트의 모든 요소를 현재 리스트에 추가합니다.
1
2
3
4
5
6
fruits = ['apple', 'banana', 'cherry']
more_fruits = ['elderberry', 'grape']
fruits.extend(more_fruits)
print(fruits) # 출력: ['apple', 'banana', 'cherry', 'elderberry', 'grape']
2.3. insert()
insert() 메서드는 지정된 위치에 요소를 삽입합니다.
1
2
3
fruits = ['apple', 'banana', 'cherry']
fruits.insert(1, 'blueberry')
print(fruits) # 출력: ['apple', 'blueberry', 'banana', 'cherry']
2.4. remove()
remove() 메서드는 첫 번째로 찾은 특정 값을 삭제합니다.
1
2
3
fruits = ['apple', 'banana', 'cherry', 'elderberry', 'grape']
fruits.remove('banana')
print(fruits) # 출력: ['apple', 'cherry', 'elderberry', 'grape']
2.5. pop()
pop() 메서드는 지정된 위치의 요소를 제거하고 그 요소를 반환합니다.
1
2
3
4
fruits = ['apple', 'banana', 'cherry', 'elderberry', 'grape']
second_fruit = fruits.pop(1)
print(second_fruit) # 출력: banana
print(fruits) # 출력: ['apple', 'cherry', 'elderberry', 'grape']
index를 지정하지 않으면 마지막 요소를 제거하고 반환합니다.
1
2
3
4
fruits = ['apple', 'banana', 'cherry', 'elderberry', 'grape']
last_fruit = fruits.pop()
print(last_fruit) # 출력: grape
print(fruits) # 출력: ['apple', 'banana', 'cherry', 'elderberry']
2.6. clear()
clear() 메서드는 리스트의 모든 요소를 제거합니다.
1
2
3
fruits = ['apple', 'banana', 'cherry', 'elderberry', 'grape']
fruits.clear()
print(fruits) # 출력: []
3. 리스트 정렬 및 뒤집기
3.1. sort()
sort() 메서드는 리스트를 오름차순으로 정렬합니다. reverse=True를 지정하면 내림차순으로 정렬할 수 있습니다.
1
2
3
4
5
6
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
numbers.sort()
print(numbers) # 출력: [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
numbers.sort(reverse=True)
print(numbers) # 출력: [9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
3.2. reverse()
reverse() 메서드는 리스트의 요소 순서를 뒤집습니다.
1
2
3
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
numbers.reverse()
print(numbers) # 출력: [5, 3, 5, 6, 2, 9, 5, 1, 4, 1, 3]
4. 리스트 컴프리헨션
리스트 컴프리헨션은 리스트를 생성하는 간결하고 효율적인 방법입니다.
4.1 기본 리스트 컴프리헨션
1
2
squares = [x ** 2 for x in range(10)]
print(squares) # 출력: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
4.2 조건부 리스트 컴프리헨션
거듭제곱 중 짝수의 값만 배열로 만드는 코드입니다.
1
2
even_squares = [x ** 2 for x in range(10) if x % 2 == 0]
print(even_squares) # 출력: [0, 4, 16, 36, 64]
4.3 중첩된 리스트 컴프리헨션
2차원 배열을 flat하게 1차원 배열로 만드는 코드입니다.
1
2
3
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
flat_matrix = [num for row in matrix for num in row]
print(flat_matrix) # 출력: [1, 2, 3, 4, 5, 6, 7, 8, 9]
5. map, filter, reduce
5.1 map()
map() 함수는 리스트의 모든 요소에 특정 함수를 적용합니다. 아래 코드는 모든 요소를 거듭 제곱으로 바꿔주는 코드입니다.
1
2
3
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x ** 2, numbers))
print(squared_numbers) # 출력: [1, 4, 9, 16, 25]
5.2 filter()
filter() 함수는 리스트에서 조건을 만족하는 요소만 남깁니다.
1
2
3
numbers = [1, 2, 3, 4, 5]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # 출력: [2, 4]
5.3 reduce()
reduce() 함수는 두 인자를 취하는 함수를 첫 번째 인자로 받고, 시퀀스를 두 번째 인자로 받아 시퀀스의 첫 번째와 두 번째 원소에 함수를 적용하고, 그 결과를 다음 원소와 함께 다시 함수에 적용하는 과정을 반복하여 최종 결과를 반환합니다. (쉽게 말해 누산기라고 생각하면 됩니다)
1
2
3
4
5
from functools import reduce
numbers = [1, 2, 3, 4]
product = reduce(lambda x, y: x + y, numbers)
print(product) # 출력: 10
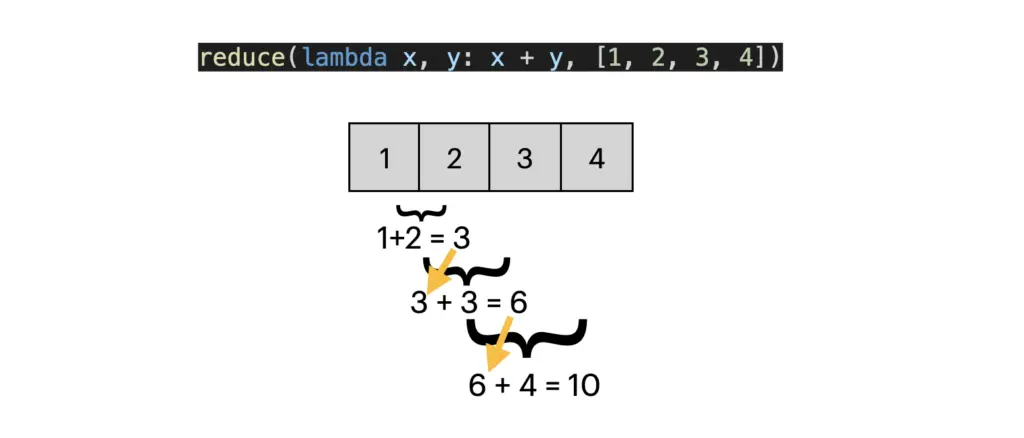 reduce
reduce
reduce() 함수는 functools 모듈을 import 해야 사용할 수 있습니다.
7. 기타 유용한 메서드
7.1. index()
index() 메서드는 리스트에서 첫 번째로 일치하는 요소의 index를 반환합니다.
1
2
3
fruits = ['apple', 'banana', 'cherry']
index = fruits.index('banana')
print(index) # 출력: 1
7.2. count()
count() 메서드는 리스트에서 특정 요소가 몇 번 나타나는지 세어 반환합니다.
1
2
3
numbers = [1, 2, 3, 2, 2, 4, 2]
count = numbers.count(2)
print(count) # 출력: 4
7.3. copy()
copy() 메서드는 리스트의 얕은 복사본(Shallow Copy)을 반환합니다.
1
2
3
fruits = ['apple', 'banana', 'cherry']
fruits_copy = fruits.copy()
print(fruits_copy) # 출력: ['apple', 'banana', 'cherry']
- 얕은 복사 (Shallow Copy)
- 객체의 최상위 레벨만 복사하고, 내부의 중첩된 객체들은 원본 객체와 참조를 공유합니다. 따라서 중첩 객체를 변경하면 원본 객체도 변경될 수 있습니다.
- 깊은 복사 (Deep Copy)
- 객체의 모든 레벨을 재귀적으로 복사하여 원본 객체와 완전히 독립적인 복사본을 만듭니다. 따라서 중첩 객체를 변경해도 원본 객체는 영향을 받지 않습니다.
7.4. sum()
sum() 함수는 리스트의 모든 숫자의 합을 반환합니다.
1
2
3
numbers = [1, 2, 3, 4, 5]
total = sum(numbers)
print(total) # 출력: 15
7.5. any()와 all()
any() 함수는 리스트에 하나라도 True 값이 있으면 True를 반환합니다. all() 함수는 리스트의 모든 값이 True이면 True를 반환합니다.
1
2
3
bool_list = [True, False, True]
print(any(bool_list)) # 출력: True
print(all(bool_list)) # 출력: False
8. 결론
Python의 list 자료형은 다양한 내장 함수와 메서드를 제공합니다. 이 글에서는 list를 다룰 때 알면 좋은 주요 함수에 대해 소개했습니다.